
Direct Data API is a new class of API that provides high-speed read-only data access to Vault. Direct Data API is a reliable, easy-to-use, timely, and consistent API for extracting Vault data.
It is designed for organizations that wish to replicate large amounts of Vault data to an external database, data warehouse, or data lake. Common use cases include:
Direct Data API is not designed for real-time application integration.
In v24.1+, this API supports the extraction of Vault objects, document versions, picklists, workflows, and audit logs.
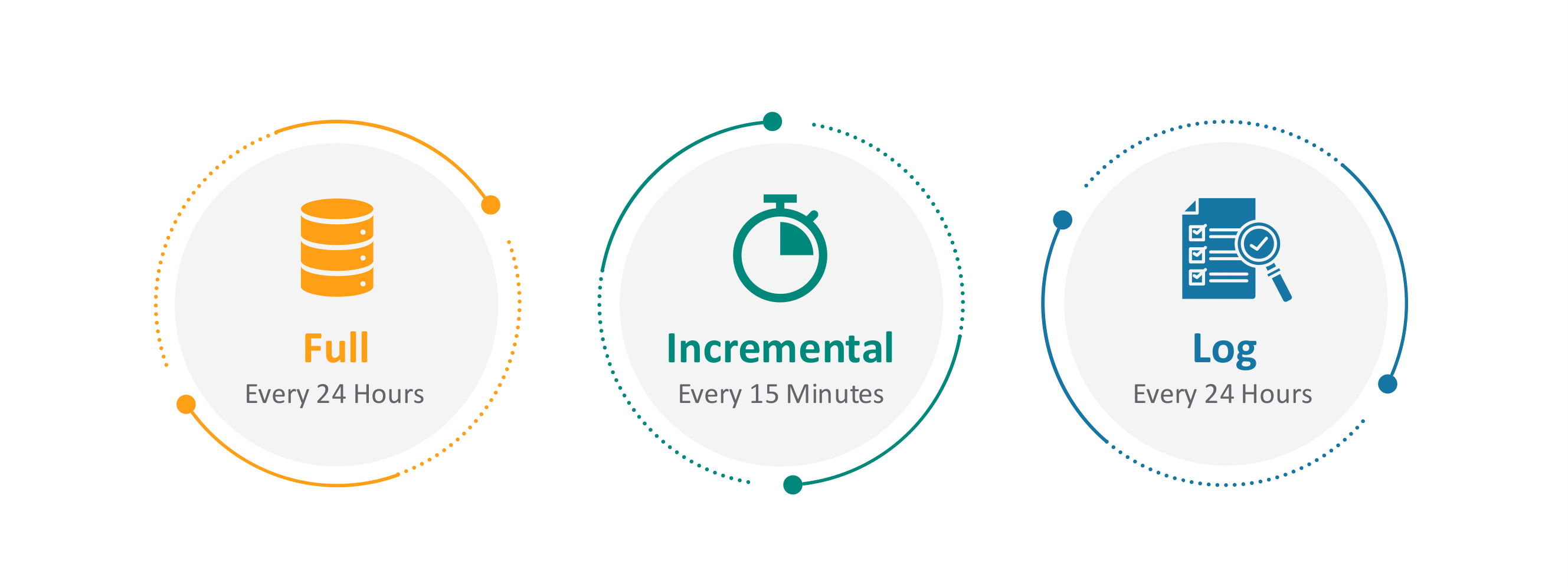
Direct Data API provides the following file types:
Learn more about each Direct Data file type in Understanding Direct Data Files, or our video walkthroughs.
Direct Data API extracts the following data from your Vault:
Direct Data API is not configurable, and all of the above data is always made available. You can use or ignore the data in the files.
There are several benefits of using Direct Data API to extract data from your Vault:
A Direct Data file is produced in a fixed, well-defined, and easy-to-understand format. This simplifies integrations, as the user doesn’t need to know the data model of the components or make multiple calls to different endpoints to build the dataset.
However, Direct Data API does include the data model for all the objects and documents in a single metadata.csv file so that tables can be created in the external system based on the data provided.
Direct Data API continuously collects and stages the data in the background and publishes it as a single file for the interval specified. This is significantly faster than extracting the data via traditional APIs, which may require multiple calls based on the number of records being extracted.
Files are always published at fixed times and at a regular cadence. Direct Data API provides Incremental files every 15 minutes, tracking changes in a 15-minute interval, which makes it possible to update the data warehouse on a more timely basis.
Direct Data API provides a transactionally consistent view of data across Vault at a given time, called stop_time.
This section outlines how to send requests to Direct Data API to retrieve the desired data from your Vault. You can send individual requests to Direct Data API using the Vault Postman Collection or use the Shell script we’ve provided to download the latest available Direct Data file. Learn more about the structure of each Direct Data file in Understanding Direct Data Files.
You can retrieve and download Direct Data files by sending requests to Direct Data API. Before calling the API, you must enable Direct Data in your Vault. In limited release Vaults, enable this feature in your Vault by navigating to Admin > Settings > General Settings and selecting Enable Direct Data API. In general release Vaults, enable this feature by contacting Veeva Support. The ability for Admins to enable this feature will be available to general release Vaults in 25R2.
Once enabled, Vault generates the first Full file and you can successfully send requests to the following endpoints:
Learn more about these endpoints in our video walkthrough and the Vault API Reference.
Direct Data API provides the following options to help filter the Direct Data files available for download:
When using the Retrieve Available Direct Data Files endpoint, the extract_type query parameter allows you to filter based on file type. For example, you can filter to retrieve only Incremental, Full, or Log files. This is helpful for integration processes which only need certain file types.
When using the Retrieve Available Direct Data Files endpoint, you can use the start_time and stop_time query parameters to filter on a specific window of time for which data was captured in the Direct Data file. For example, you may want to retrieve all Incremental files generated within an hour timeframe, from 2025-01-15T07:00:00Z to 2025-01-15T08:00:00Z.
All Full files have a start time of 00:00 Jan 1, 2000. To include Full files in your results when filtering by time, you must use 00:00 Jan 1, 2000 or earlier as your start_time. Otherwise, Direct Data API only returns Incremental files for the specified window of time.
When using the Retrieve Available Direct Data Files endpoint, each returned file includes a record_count attribute that can help locate empty files. This attribute provides the total number of records for all extracts in the file. If this count is zero (0), it means no data changes were captured in the time interval for which the file was produced. Therefore, there is no need to send a request to Direct Data API to download a file with record_count=0.
As an integration best practice, we recommend designing your integration to check for files with record_count=0 and, if true, skip the API call to retrieve said files. This results in faster integrations because it eliminates the need to spend time processing empty files.
When Direct Data API is enabled for the first time, Vault extracts a Full file and publishes it at 1:00 AM UTC. The time it takes to prepare the first Full file depends on when the feature was enabled and how much data is present in your Vault. Depending on what day Direct Data API was enabled in your Vault, the first Full file may not be available until the following day. Veeva can help provide an estimate for when the first Full file will be available after the feature is enabled in your Vault. Direct Data API returns a standard error message until the first Full file is generated.
As an alternative to using the Vault Postman Collection, you can use the example Shell script below to download Direct Data files from your Vault. The script uses your provided credentials and the filters specified to download all file parts of the latest available Direct Data file.
The script requires the following variables:
full_directdata, incremental_directdata, or log_directdataYYYY-MM-DDTHH:MMZ. Always use 2000-01-01T00:00Z if extract_type=full_directdata.YYYY-MM-DDTHH:MMZ.This script runs natively in OSX/UNIX systems. On Windows operating systems, the script requires Bash. If you have Git installed, you can use Git Bash.
Run this script from the directory where you would like to download the Direct Data file. If there are multiple file parts, the script combines them into a single .tar.gz file.
![]()
Click to expand the code example.
# Add the vault_dns of your Vault
vault_dns="your-vault.veevavault.com"
# Add in your session ID
session_id="YOUR_SESSION_ID"
# Add "full_directdata", "incremental_directdata", or "log_directdata"
extract_type="full_directdata"
# For "full_directdata" always use 2000-01-01T00:00Z as the start_time
start_time="2000-01-01T00:00Z"
# Add the stop_time
stop_time="2024-06-01T15:15Z"
# Will place the files in the current folder where the script runs
target_directory="$(pwd)"
# Perform the API call to retrieve the list of Direct Data files
direct_data_file_list_response=$(curl -s -X GET -H "Authorization: $session_id" \
-H "Accept: application/json" \
"https://$vault_dns/api/v24.1/services/directdata/files?extract_type=$extract_type&start_time=$start_time&stop_time=$stop_time")
# Extract the response status from the API response
response_status=$(echo "$direct_data_file_list_response" | grep -o '"responseStatus":"[^"]*' | sed 's/"responseStatus":"//')
# Check if the API call was successful
if [ "$response_status" != "SUCCESS" ]; then
error_message=$(echo "$direct_data_file_list_response" | grep -o '"message":"[^"]*' | sed 's/"message":"//' | tr -d '"')
if [ -z "$error_message" ]; then
printf "Retrieve Available Direct Data Files call failed. Exiting script.\n"
else
printf "Retrieve Available Direct Data Files call failed with error: %s\n" "$error_message"
fi
exit 1
else
printf "Retrieve Available Direct Data Files call succeeded.\n"
# Extract data array
data=$(echo "$direct_data_file_list_response" | grep -o '"data":\[[^]]*\]' | sed 's/"data":\[//' | tr -d ']')
# Count file parts
fileparts=$(echo "$data" | grep -o '"fileparts":[0-9]*' | sed 's/"fileparts"://')
# Check if fileparts is null or empty
if [ -z "$fileparts" ]; then
printf "No Direct Data Extract Files found for '$extract_type' with start_time = '$start_time' and stop_time = '$stop_time'.\n"
exit 0
fi
if [ "$fileparts" -gt 1 ]; then
printf "Multiple file parts.\n"
# Handling multiple file parts
filepart_details=$(echo "$data" | grep -o '"filepart_details":\[{"[^]]*' | sed 's/"filepart_details":\[//' | tr -d ']')
filepart_details=$(echo "$filepart_details" | sed 's/},{/}\n{/g')
filename=$(echo "$data" | grep -o '"filename":"[^"]*' | sed 's/"filename":"//' | tr -d '"' | head -n 1)
while IFS= read -r filepart_detail; do
filepart_url=$(echo "$filepart_detail" | grep -o '"url":"[^"]*' | sed 's/"url":"//' | tr -d '"')
output_filepart_name=$(echo "$filepart_detail" | grep -o '"filename":"[^"]*' | sed 's/"filename":"//' | tr -d '"')
curl -o "$output_filepart_name" -X GET -H "Authorization: $session_id" \
-H "Accept: application/json" \
"$filepart_url"
done <<< "$filepart_details"
# Combine file parts
name=$(echo "$data" | grep -o '"name":"[^"]*' | sed 's/"name":"//' | tr -d '"' | head -n 1)
cat "$name."* > "$filename"
full_path="$target_directory/$name"
if [ ! -d "$full_path" ]; then
# Directory does not exist, create it
mkdir -p "$full_path"
printf "Directory '%s' created.\n" "$full_path"
else
printf "Directory '%s' already exists.\n" "$full_path"
fi
tar -xzvf "$filename" -C "$full_path"
else
printf "Only one file part.\n"
# Handling single file part
filepart_detail=$(echo "$data" | grep -o '"filepart_details":\[{"[^]]*' | sed 's/"filepart_details":\[//' | tr -d '{}')
filepart_url=$(echo "$filepart_detail" | grep -o '"url":"[^"]*' | sed 's/"url":"//' | tr -d '"')
filename=$(echo "$data" | grep -o '"filename":"[^"]*' | sed 's/"filename":"//' | tr -d '"' | head -n 1)
curl -o "$filename" -X GET -H "Authorization: $session_id" \
-H "Accept: application/json" "$filepart_url"
name=$(echo "$data" | grep -o '"name":"[^"]*' | sed 's/"name":"//' | tr -d '"' | head -n 1)
full_path="$target_directory/$name"
if [ ! -d "$full_path" ]; then
# Directory does not exist, create it
mkdir -p "$full_path"
printf "Directory '%s' created.\n" "$full_path"
else
printf "Directory '%s' already exists.\n" "$full_path"
fi
tar -xzvf "$filename" -C "$full_path"
fi
fi
A Direct Data file is a .gzip file that includes a set of data entities as CSV files called extracts. You cannot directly create or modify Direct Data extracts, and the available extracts may vary depending on the Vault application.
Direct Data files are categorized under the following types:
stop_time and each file is available to download for ten (10) days. For example, a window of 02:00-02:15 UTC will result in an Incremental file published at 02:30 UTC. Learn more about transaction times for Incremental files and how they capture user logins.The following image shows the folder structure for a Full Direct Data file:
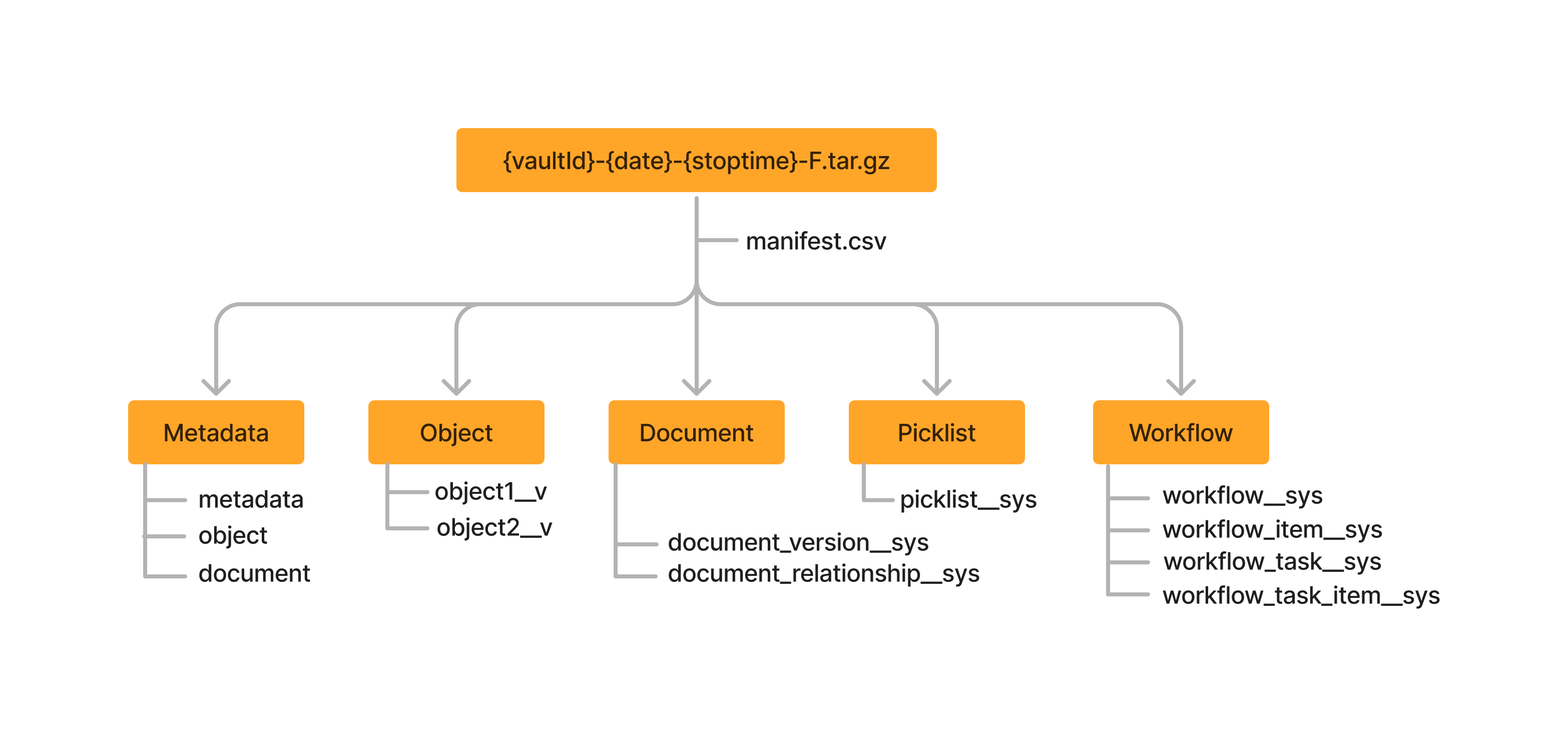
Each file is named according to the following format: {vaultid}-{date}-{stop_time}-{type}.tar.gz.{filepart}. The file name is comprised of the following variables:
vaultid: Refers to the Vault’s IDdate: Refers to the date that the file was created (in YYYYMMDD format)stop_time: Refers to the stop time in UTC of the interval (in HHMM format)type: Refers to the type of the file (N: Incremental, F: Full, L: Log)filepart: Refers to the part number of the file. Files greater than 1 GB in size are split into parts to keep downloads manageable (in NNN format). Learn more about working with file parts.For example, 143462-20240123-0000-F.tar.gzip.001 indicates the first file part of a Full Direct Data file from a Vault with ID 143462 that contains data from the time the Vault was created to January 23, 2024, 00:00 UTC.
By default, Direct Data API publishes Full and Log files at 01:00 Vault Time without adjusting for daylight saving time (DST). Since the schedule is based on the Vault’s standard time and remains fixed in UTC year-round, the local delivery time will shift during DST. Furthermore, the stop_time indicated in file names and all timestamps within the files always remain in UTC.
For example, if your Vault is configured for the Pacific Time zone:
45277-20261108-0800-F.tar.gz.45277-20260408-0800-F.tar.gz.When an Admin changes the Vault’s time zone, the scheduled extraction time updates accordingly. To ensure no gap between extracts, Direct Data API generates an additional Full and Log file at the previous time zone’s scheduled time, followed by a new Full and Log file at the new time zone’s schedule. Because of this transition, there will be up to three Full files available for a short period of time. Depending on the time of day the change is made, there may also be a one-time delay of up to 24 hours to produce the next scheduled file. Learn more about the Vault time zone.
The manifest.csv file provides definitive information about what is included in the file, as well as the record count for each extract. This file is always present under the root folder.
The manifest CSV file includes the following columns to describe each extract:
| Column Name | Description |
|---|---|
extract | The extract name, in the format {component}.{extract_name}. For example, Object.user__sys. |
extract_label | The extract label. For example, if the extract name is Object.user__sys, the extract label is User. |
type | The type of extract: updates or deletes. This column only appears if the extract_type is incremental_directdata. |
records | The number of records for a given extract. This may show as zero records if there is no data for the given time period. |
file | Relative path to the CSV file within the Direct Data .gzip file. This column may not show a file if there are zero records for a given extract. |
The metadata.csv file defines the structure of each extract so that consumers can understand the structure of the extract CSV. The metadata.csv is available in the Metadata folder of a Full Direct Data file.
Incremental files include the metadata that has changed in the interval. Within an Incremental file’s Metadata folder, there may be a metadata_deletes.csv file if there have been any metadata deletions over the 15-minute interval, such as the removal of a field from an object’s configuration. There is also a metadata_full.csv under the root folder which includes the metadata of all Vault data. This file is identical to the metadata.csv file in a Full file and helps consumers look at all metadata of the Vault regardless of the changes that are captured in an Incremental file. The manifest.csv does not list this file.
The metadata CSV file includes the following standard columns in the following order:
| Column Name | Description |
|---|---|
modified_date | The date the field’s configuration was last updated. This value is null within the metadata.csv of a Full file and the metadata_full.csv of an Incremental file. |
extract | The extract name, in the format {component}.{extract_name}. For example, Object.user__sys or Document.document_version__sys. |
extract_label | The extract label. For example, if the extract name is Object.user__sys, the extract label is User. |
column_name | Name of the column in the extract. For example, description__c. |
column_label | The column label in the extract. For example, if the column name is description__c, the column label is Description. |
type | The indicated data type of the column: String, LongText, Number, Date, DateTime, Relationship, MultiRelationship, Picklist, MultiPicklist, or Boolean. |
length | For columns where the type value is String or LongText, this provides the length of the field. |
related_extract | For columns where the type value is Relationship, Picklist, or MultiPicklist, this indicates the name of the related extract. |
Extracts contain the data for Vault components. Log Direct Data files only contain audit log extracts. Full and Incremental files may contain extracts for the following components:
Direct Data API populates an extract’s CSV file name according to its extract_name. In addition, if a user deletes object records or document versions, Direct Data API stores it in a separate file by appending _deletes.csv to the extract name. The CSV files include a column referencing the record ID of related objects (which can be identified using the metadata.csv). In all extracts, standard columns appear first, while the remaining columns are ordered alphabetically. While this order is predictable, schema changes in your Vault may alter column positioning within extracts. The columns and content available in each extract vary depending on the component, and are elaborated on in the sections below.
Document version data is available in the document_version__sys.csv file. Deleted document versions are tracked in a separate file.
All document extracts have a set of standard fields in addition to all the defined document fields in Vault. Extracts also include all queryable document fields.
The following standard columns are available in the document version extract:
| Column Name | Description |
|---|---|
id | The document version ID, in the format {doc_id}_{major_version_number}_{minor_version_number}. For example, 101_0_1 represents version 0.1 of document ID 101. This value is the same as version_id. |
modified_date__v | The date the document version was last modified. |
doc_id | The document id field value. |
version_id | The document version ID, in the format {doc_id}_{major_version_number}_{minor_version_number}. For example, 101_0_1 represents version 0.1 of document ID 101. This value is the same as id. |
major_version_number | The major version of the document. |
minor_version_number | The minor version of the document. |
type | The document type. |
subtype | The document subtype. |
classification | The document classification. |
source_file | The Vault API request to download the source file using the Download Document Version File endpoint. |
rendition_file | The Vault API request to download the rendition file using the Download Document Version Rendition File endpoint. |
text_file | The Vault API request to export the plain text of the source file using the Download Document Text endpoint. |
Direct Data API includes document metadata in the document_version__sys extract. This file includes additional attributes such as source_file, rendition_file, and text_file, which have generated URLs to download the content for that particular version of a document.
If your organization needs to make the source content for all documents available for further processing or data mining, use the Export Document Versions endpoint to export documents to your Vault’s file staging server in bulk. This endpoint allows up to 10,000 document versions per request.
Document relationship data is available in the document_relationship__sys.csv file. If there are deleted document relationships, they are tracked in a separate document_relationship__sys_deletes.csv.
The following standard columns are available in the document relationships extract:
| Column Name | Description |
|---|---|
id | The document relationship ID. |
modified_date__v | The date the document relationship was last modified. |
modified_by__v | The ID of the user who last modified the document relationship. |
source_doc_id__v | The ID of the source document on which the relationship originates. |
source_version_id | The version ID of the source document, in the format {source_doc_id__v}_{source_major_version__v}_{source_minor_version__v}. For example, 101_0_1 represents version 0.1 of document ID 101. |
source_major_version__v | The major version of the source document. If the document relationship is not version-specific, this value is empty. |
source_minor_version__v | The minor version of the source document. If the document relationship is not version-specific, this value is empty. |
target_doc_id__v | The ID of the target document to which the relationship points. |
target_version_id | The version ID of the target document, in the format {target_doc_id__v}_{target_major_version__v}_{target_minor_version__v}. For example, 101_0_1 represents version 0.1 of document ID 101. This value is the same as id. |
target_major_version__v | The major version of the target document. If the document relationship is not version-specific, this value is empty. |
target_minor_version__v | The minor version of the target document. If the document relationship is not version-specific, this value is empty. |
relationship_type__v | The type of relationship between the source and target document. |
source_vault_id__v | The ID of the source Vault for a Crosslink document relationship. |
created_date__v | The date the document relationship was created. |
created_by__v | The ID of the user who created the document relationship. |
Each object has its own extract file. Extracts are named according to their object name. For example, the extract CSV file for the Activity object is named activity__v.csv. If there are deleted records for an object, they are tracked in a separate {objectname}_deletes.csv.
Both custom and standard objects from your Vault are included. All objects visible on the Admin > Configuration page of your Vault are available for extraction.
All object extracts have a set of standard fields in addition to all of the defined fields included on the object, including inactive fields. The following standard columns are available in Vault object extracts:
| Column Name | Description |
|---|---|
id | The object record ID. |
modified_date__v | The date the object record was last modified. |
name__v | The name of the object record. |
status__v | The status of the object record. |
created_by__v | The ID of the user who created the object record. |
created_date__v | The date the object record was created. |
modified_by__v | The ID of the user who last modified the object record. |
global_id__sys | The global ID of the object record. |
link__sys | The object record ID across all Vaults where the record exists. |
All picklist data is available in the picklist__sys.csv file. Picklist values cannot be deleted, only inactivated. When a picklist value name is changed, the separate picklist__sys_deletes.csv file tracks the original value, while the picklist__sys.csv file shows the new value. Learn more about picklist deletion in Vault Help.
This does not include picklists that are not referenced by any objects or documents. Learn more about picklist references.
The following standard columns are available in picklist extracts:
| Column Name | Description |
|---|---|
modified_date__v | The date the picklist was last modified. |
object | The name of the object on which the picklist is defined. |
object_field | The name of the object picklist field. |
picklist_value_name | The picklist value name. |
picklist_value_label | The picklist value label. |
status__v | The status of the picklist value. |
Workflow data including workflow instances, items, user tasks, and task items is available in the following extracts:
workflow__sys.csv: Provides workflow-level information about each workflow instance.workflow_item__sys.csv: Provides item-level information about each document or object record associated with a workflow.workflow_task__sys.csv: Provides task-level information about each workflow task associated with a workflow.workflow_task_item__sys.csv: Provides item-level information about each workflow task associated with a workflow.All workflow data in extracts includes active and inactive workflows for both objects and documents. A Direct Data file may include additional extracts for legacy workflows.
The workflow__sys.csv extract provides workflow-level information about each workflow instance, including the workflow ID, workflow label, owner, type, and relevant dates.
The workflow_item__sys.csv provides item-level information about each document or object record associated with a workflow, including the workflow instance ID, item type, and IDs of the related Vault object record or document. If a workflow includes a document, the Document Version ID (doc_version_id) column in the CSV file references the document version it’s related to. If the workflow instance is not related to a specific document version, this column displays the latest version ID of that document. If the extract_type is incremental_directdata, the Incremental file captures new document versions associated with the workflow.
The metadata CSV file assigns the workflow item extract a type of String.
The workflow_task__sys.csv provides task-level information about each user task associated with a workflow. This extract includes information such as the workflow ID, task label, task owner, task instructions, and relevant dates. This extract excludes participant group details.
The workflow_task_item__sys.csv provides item-level information about each user task associated with a workflow, such as the workflow task item ID, any captured verdicts, and the type of task item.
Direct Data extracts may contain data about your Vault’s active and inactive legacy workflows.
Active legacy workflow information is available in the following extracts:
active_legacy_workflow__sys.csv: Provides workflow-level information about active legacy workflows and workflow items.active_legacy_workflow_task__sys.csv: Provides task-level information about active legacy workflow tasks and task items.Incremental files do not include inactive legacy workflow data, however, this information is accessible from a Full file. The extract for inactive legacy workflows only includes data from the previous day. To retrieve all inactive legacy workflow data, we recommend exporting a report via the Vault UI.
Inactive legacy workflow information is available in the following extracts:
inactive_legacy_workflow__sys.csv: Provides workflow-level information about inactive legacy workflows and workflow items.inactive_legacy_workflow_task__sys.csv: Provides task-level information about inactive legacy workflow tasks and task items.Log files contain extracts that capture audit log data for a single day, which are not included in Full or Incremental files. Direct Data API publishes each Log file once a day at 01:00 UTC and this file is available to download for two (2) days following its publishing. Log data, including detailed changes for object records and documents, system configuration changes, and login information, is captured within the following extracts:
object_audit_trail.csv: Provides all changes to object records. Each event includes information such as the timestamp, user’s login name, affected item, and description. Vault only captures changes to object records when the Audit data changes in this object setting is enabled on that object.document_audit_trail.csv: Provides document-related events, including views, send as link actions, task completions, and modifications to document fields. Each event includes information such as the timestamp, user’s login name, affected item, and description.system_audit_trail.csv: Provides Vault-level configuration and settings changes. Each event includes information such as the timestamp, the user who performed the change, the affected item, and the event description.login_audit_trail.csv: Provides user authentication events, including users’ logins, failed login attempts, and password changes. Each event includes information such as the timestamp, user’s login name, originating IP address, type of event, user’s browser, user’s platform, and Vault ID.To see which standard columns are included in each Log file extract, refer to metadata_full.csv under the root folder. The Log folder only contains the extracts whose audit trails have been updated for the day. For example, if no users have logged in today, the Log folder will not include the login_audit_trail.csv file. Learn more about audit logs in Vault Help.
With the availability of Incremental files with Direct Data API, Vault has a consistent way to capture and report on data changes that are committed to the database in 15-minute increments. This ensures that Direct Data API provides a fully consistent data state based on the committed data.
However, Incremental files only include Vault events that are committed to the database within a given time frame. The database commit time may differ from the last modified time. The last modified time may be updated by long-running transactions such as jobs, cascading state changes, or even triggers that create additional entities as part of an SDK job.
Direct Data API captures user logins as events within the user__sys.csv extract file even if no additional changes were made to the User object record, including if the record’s modified_date__v value remains unchanged.
Ensuring the reliable delivery of Direct Data files is paramount. If Direct Data API fails to publish a file for a specific time interval, the response includes an error object containing the file’s name, the next_retry time in UTC, and a standard message. If Direct Data API successfully publishes the file at the next_retry time, the response then includes the metadata for that file, thus replacing the error object.
This section outlines how to build an integration with Direct Data API in addition to best practices for your integration. To see a working example of a Direct Data API integration, see our open-source accelerators, which you can use as a starting point to build your custom integration.
The following diagram visualizes how an integration processes Direct Data files extracted from Vault to populate an external data lake or warehouse.
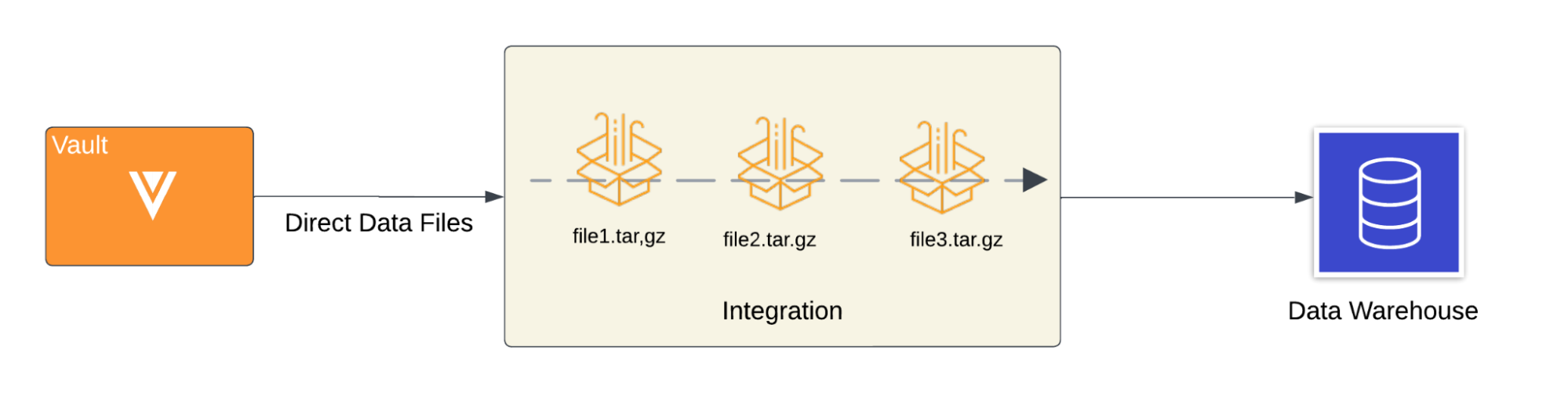
To learn more about the interaction between Direct Data API and your external data lake or warehouse, see our integration flow example diagram.
As outlined in this guide, your integration should be able to perform the following functions:
This guide references the following terms:
The sequence diagram below visualizes the interaction flow between an external data lake and Direct Data API. It illustrates the steps involved in requesting a Direct Data file, including authentication, initiating the data export process, retrieving the generated file, and subsequent data processing. The diagram highlights the communication between the client application and the Vault server, clarifying the sequence of API calls and responses. This visual guide simplifies understanding of the end-to-end process and helps developers implement their integration logic effectively.
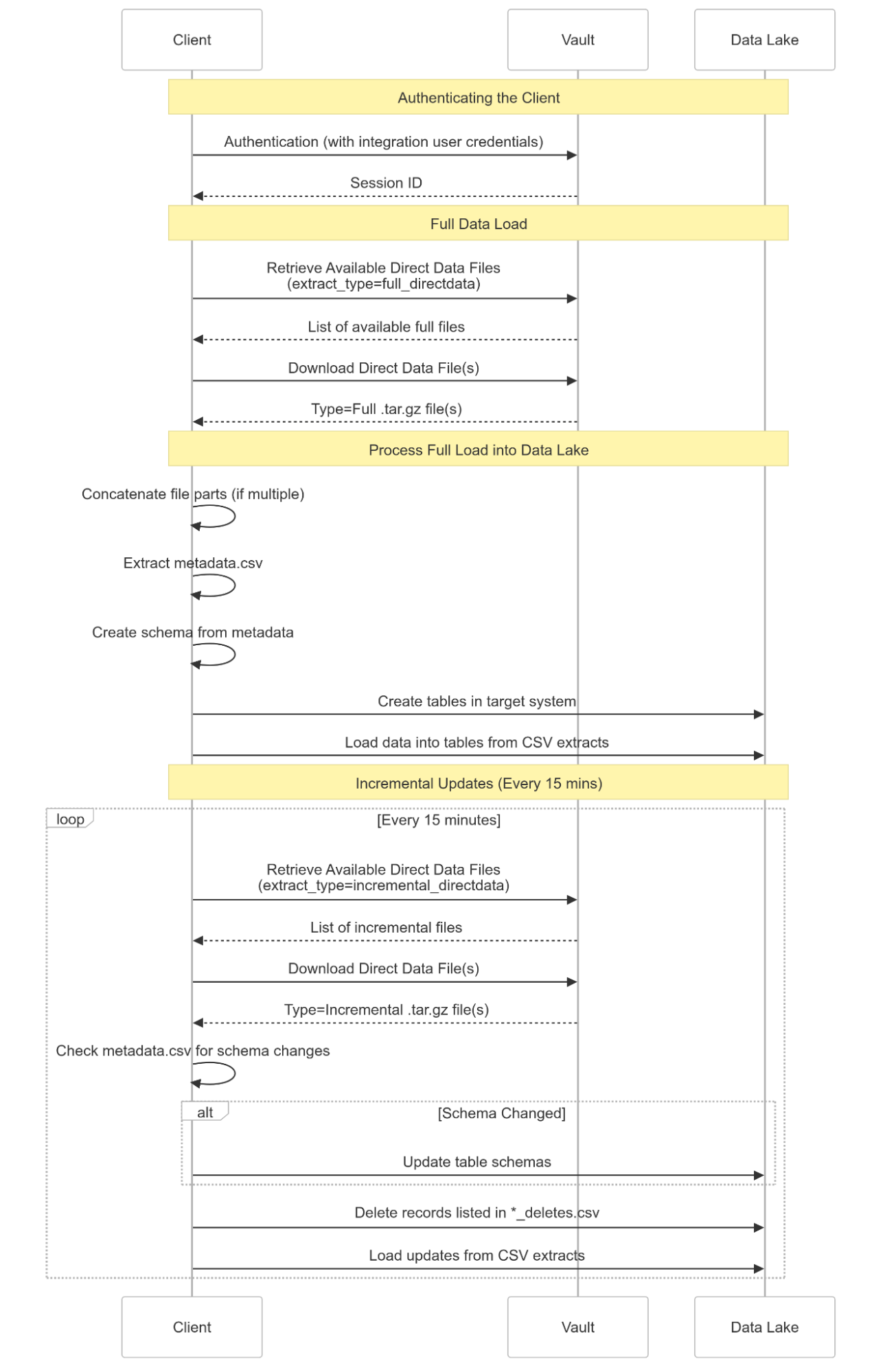
To access the source system data, you must first enable Direct Data API in your Vault by navigating to Admin > Settings > General Settings and selecting Enable Direct Data API. Once Direct Data API is enabled, perform the following steps:
Learn more about sending requests to these endpoints in our video walkthrough.
To stage the source system data retrieved in the previous step, you must create a separate location to store the Direct Data files once downloaded, such as an object storage service.
If a Direct Data file is greater than 1GB in size, it may have multiple parts. If your Direct Data file has multiple parts, concatenate the files into a valid .gzip file before use. Learn more in Working with File Parts.
Once Direct Data API successfully extracts the desired files to the staging location, you can start loading them into your target system.
Utilize the following files nested within a Direct Data file to assist with building tables in your target system:
metadata.csv: This file provides the schema for all the components that are present in the Direct Data file. Any referenced data is defined with type=Relationship and the related extract is specified in the metadata.csv. Use this data to define tables in your database.manifest.csv: This file provides an inventory of all extracts and lists the record count for each extract.Learn more about the contents of a Direct Data file in Understanding Direct Data Files.
For the initial load into the target system, you will always work with a Full file. This contains all Vault data captured from the time the Vault was created until the stop_time of the file.
To load an extract into the database, simply load an extract CSV as a table with the schema already defined. For example, if you are loading Vault data into Amazon Redshift, once the extracts are stored in an S3 bucket, you can use the COPY command to load the table from the extract to create a table in Amazon Redshift. Below is a code example that provides a way to do this with data stored in AWS S3:
Click to expand the Python script example.
f"COPY {dbname}.{schema_name}.{table_name} ({csv_headers}) FROM '{s3_uri}' " \
f"IAM_ROLE '{settings.config.get('redshift', 'iam_redshift_s3_read')}' " \
f"FORMAT AS CSV " \
f"QUOTE '\"' " \
f"IGNOREHEADER 1 " \
f"TIMEFORMAT 'auto'" \
f"ACCEPTINVCHARS " \
f"FILLRECORD"
Once all the tables have been populated with the data in the extracts, you have successfully replicated all Vault data in your target system up until the stop_time of the Full file. Following this step, you may choose to verify the data in your target system prior to loading incremental data.
To keep the target system up to date with the latest data in your Vault, you must configure your integration to download Incremental Direct Data files and load any changes.
Incremental files capture creates, updates, and deletes made to the data in your Vault. If the same piece of data has undergone multiple changes within the same time window indicated for an Incremental file, its extract will only reflect the most recent change. We recommend loading the target system with deletes before loading creates and updates, which are captured in a separate file.
Vault Admins can easily make configuration changes to their Vault using the UI, Vault API, Vault Loader, or a Vault Package (VPK). Additionally, Vault Releases, which occur three times a year, may result in a number of schema changes. Learn more in Vault Release Upgrades and Direct Data API.
The metadata.csv of an Incremental Direct Data file captures schema changes, therefore, your integration should check this file for schema changes before updating any tables in the target system.
Schema changes may include the addition or removal of fields on objects and documents, which may alter the ordering of columns in extract files. Instead of fetching data according to its position within an extract, your integration should fetch data by field name.
Once the data is loaded in the target system, you will need to verify that the data in your Vault has been accurately replicated in your target system.
You can achieve this by querying Vault for some filtered data and compare it to the results obtained by querying your target system. Results may vary slightly if data in Vault has changed since it was extracted using Direct Data API.
The following best practices should be kept in mind when incorporating Direct Data into new or existing integrations.
Direct Data API publishes Direct Data files at fixed times in a day. For example, for a data extraction window of 13:00 to 13:15 UTC, the corresponding Incremental file will be published at 13:30 UTC. This means an integration can check and request the file at 13:30 UTC or after. This reduces the number of requests to the API to check if a file is available and makes your code simpler to manage.
A Direct Data file name always includes a file part number. If the compressed file is over 1 GB, then the file is broken into 1 GB parts to simplify the downloading of very large files. After downloading all the file parts, you should concatenate the files into a valid .gzip file before use. Each part in itself is not readable.
Below is a code example to handle multiple file parts:
Click to expand the Python script example.
try:
for file_part in directDataItem.filepart_details:
file_part_number = file_part.filepart
response: VaultResponse = request.download_item(file_part.name, file_part_number)
response = s3.upload_part(
Bucket=bucket_name,
Key=object_key,
UploadId=upload_id,
PartNumber=file_part_number,
Body=response.binary_content
)
part_info = {'PartNumber': file_part_number, 'ETag': response['ETag']}
parts.append(part_info)
s3.complete_multipart_upload(
Bucket=bucket_name,
Key=object_key,
UploadId=upload_id,
MultipartUpload={'Parts': parts}
)
except Exception as e:
# Abort the multipart upload in case of an error
s3.abort_multipart_upload(Bucket=bucket_name, Key=object_key, UploadId=upload_id)
log_message(log_level='Error',
message=f'Multi-file upload aborted',
exception=e,
context=None)
raise e
During a Vault release, a production Vault is typically unavailable for up to 10 minutes in a 2-hour timeframe. Each Vault release may introduce configuration updates and new components. You should expect to see a large number of updates within a short period of time in your Vault’s Direct Data files.
It is typical for a Vault to undergo data model changes with each release. Maintaining data consistency between your data warehouse or data lake and Vault requires a strategic refresh approach. Therefore, we recommend a full refresh of your replicated data once per General Vault release, or three (3) times per year. This ensures that your data warehouse or data lake accurately reflects the latest Vault schema and avoids potential inconsistencies or data corruption.
Object or document fields that reference picklist values are classified with a type of Picklist or MultiPicklist in the metadata.csv file.
The picklist extract allows you to retrieve the picklist value labels corresponding to the picklist value names referenced in other extracts. Picklist extracts should be handled in the following ways:
object, object_field, picklist_value_name). The extract and extract field metadata provide the object and object_field values, respectively.Below is an example using the masking__v picklist field on the study__v object from a Safety Vault:
| id | modified_date__v | masking__v | name__v | organization__v | study_name__v |
| V17000000001001 | 2023-12-06T17:57:05.000Z | open_label__v | Study 1 | V0Z000000000201 | Study for Evaluation of Study Product |
The corresponding entry in the metadata.csv for the picklist field would be:
| extract | extract_label | column_name | column_label | type | length | related_extract |
| Object.study__v | Study | masking__v | Masking | Picklist | 46 | Picklist.picklist__sys |
Below is an example of the Picklist.csv row for the open_label__v value of the masking__v picklist field on the study__v object:
| modified_date__v | object | object_field | picklist_value_name | picklist_value_label | status__v |
| 2023-12-14T00:06:28.867Z | study__v | masking__v | open_label__v | Open Label | active__v |
The workflow item extract (workflow_item__sys.csv) provides information about the document version or Vault object record that relates to the item. There may be instances where the referenced document version or Vault object record does not have a corresponding extract in the Direct Data file. For example, when you retrieve an Incremental file, its extracts only contain data updated within the specified 15-minute interval. Therefore, if the document version or object record was not modified within this interval, it will not have its own extract.
As best practice, your external data warehouse should allow for a polymorphic relationship between the workflow item extract and each of the tables representing object extracts.
The following best practices should be kept in mind when handling field data extracted from your Vault with Direct Data API.
Direct Data API only evaluates formula fields during initial staging (for Full files) or when a record change occurs (for an Incremental file). Other endpoints of Vault API evaluate formula fields every time a record is requested. For example, if a formula field contains Today(), the only time the formula field value will be the same between Direct Data API and Vault API is on a day when the record has changed.
When configured, a formula field can display as an icon based on the formula’s evaluation. Direct Data API handles icon formula fields in a unique way. While these fields are represented as a single character in length within the Direct Data file’s metadata, they can contain additional metadata representing the alternative text for the icon. This alternative text can be up to 3,968 characters long and offers context about the icon.
When working with MultiRelationship type document fields that reference multiple objects, set the maximum length of such fields to 65,535 bytes in your external system to avoid truncated data.
Rich Text fields present a unique challenge when extracting data. While Vault’s user interface limits the plain text portion of Rich Text content to 32,000 characters, the underlying storage and the Direct Data export handle these fields differently. To accommodate potential markup and ensure data integrity, Direct Data API metadata always reports a length of 64,000 characters for Rich Text fields. While the metadata indicates a larger potential size, the plain text still adheres to Vault’s 32,000-character limit (excluding markup).
While Direct Data API provides comprehensive data extracts, associating user-facing labels with certain components requires additional integration logic. For example, document types or lifecycles. Component labels are included within the Vault Component Object extract (vault_component__v.csv), which is available in the Object folder in the .gzip Direct Data file. The examples below demonstrate how to join the relevant IDs from the main data files with the corresponding entries in the vault_component__v.csv file to obtain the correct labels for lifecycles, document types, and other related components. These queries should be executed after loading data into the Target System.
To retrieve the document type label, join the vault_component__v table on the document_version__sys table by matching component_name__v from vault_component__v with the type__v column in document_version__sys. After the join, select the label__v column from vault_component__v to obtain the document type label.
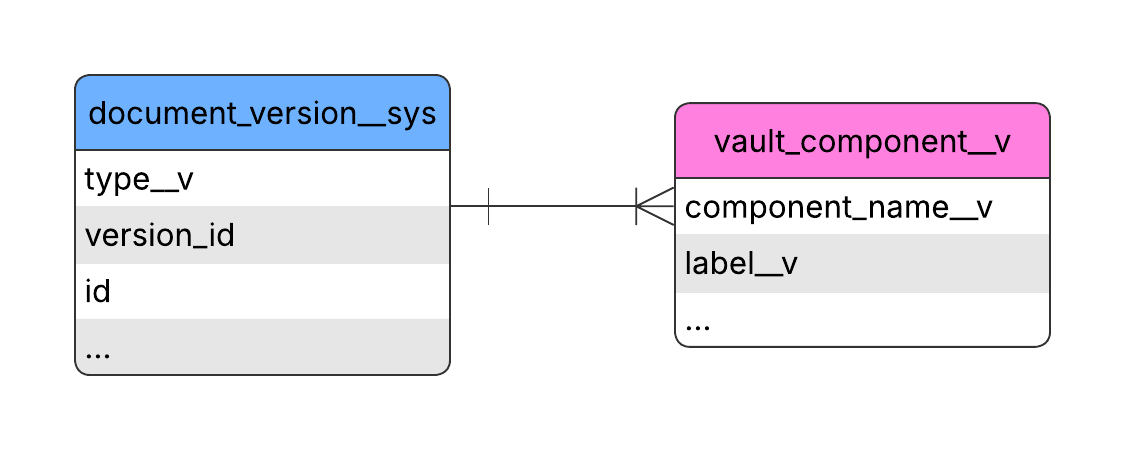
The following SQL query retrieves the document type label:
SELECT vc."label__v", vc."component_name__v", dv."type__v"
FROM document_version__sys AS dv
JOIN vault_component__v AS vc ON vc."component_name__v" = dv."type__v";
To retrieve an object record’s lifecycle label, join the vault_component__v table on the custom_object__c table by matching component_name__v from vault_component__v with the lifecycle__v column in custom_object__c. After the join, select the label__v column from vault_component__v to obtain the object record’s lifecycle label.
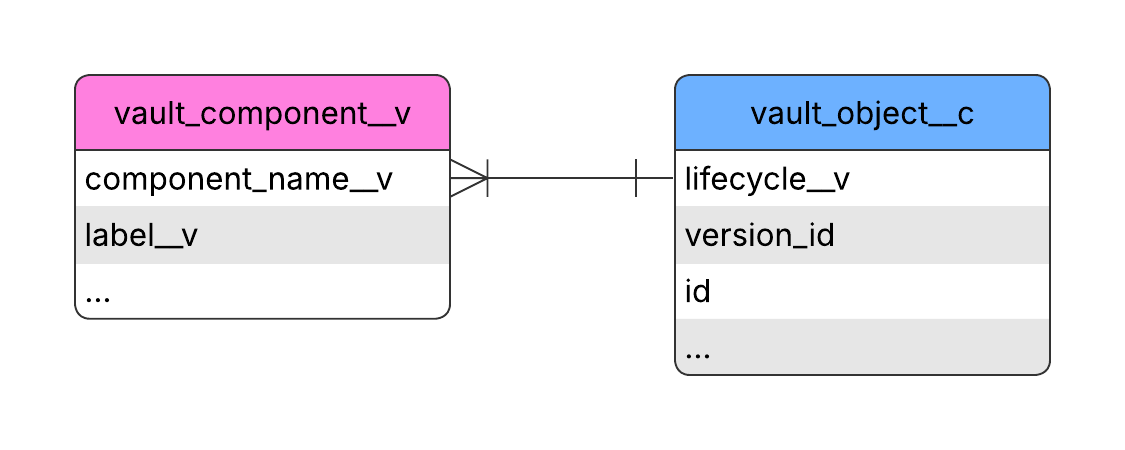
The following SQL query retrieves an object record’s lifecycle label:
SELECT vc."label__v", vc."component_name__v", co."lifecycle__v"
FROM custom_object__c AS co
JOIN vault_component__v AS vc ON vc."component_name__v" = co."lifecycle__v";
To associate user-facing labels with subcomponents, use the Retrieve Component Record endpoint to request the parent component’s metadata. This retrieval is not necessary for picklist values and object fields because their user-facing labels are provided by Direct Data API.
Maintaining data consistency between your data warehouse or data lake and Vault requires a strategic refresh approach. It is typical for a Vault to undergo data model changes with each release. Therefore, we recommend a full refresh of your replicated data once per General Vault release, or three (3) times per year. This ensures that your data warehouse or data lake accurately reflects the latest Vault schema and avoids potential inconsistencies or data corruption.
Our Vault Developer Support team has built a sample accelerators which you can use as-is with your Vault or as a starting point to build your custom integration. If you are building your own accelerator, refer to best practices for building scalable accelerators.
Each open-source accelerator performs the following fundamental processes:
The open-source accelerators listed below facilitate the loading of data from Vault to an object storage system, to then be loaded into target data systems. Additionally, if your organization relies on data visualization, each target system can connect to Power BI.
You can access the source code for these accelerators from our GitHub repository.
Building a scalable accelerator leveraging Direct Data API requires careful consideration of several key factors. Key strategies for maximizing throughput and minimizing processing time include:
COPY operations and other data processing tasks. Adequate memory prevents bottlenecks and ensures smooth data transfer.This video provides a walkthrough of the differences between a Direct Data API and a traditional API.
This video provides a walkthrough of retrieving your Direct Data files with Direct Data API endpoints, including a demo in Postman.
The following walkthroughs give an in-depth explanation of each Direct Data file type.